Streaming data replication from postgres to redshift: re_dms
We built a new tool called re_dms in order to allow streaming replication of data from postgres to redshift. Here, we’ll outline why we needed this new tool, our technical considerations,and some challenges we overcame.
IN THIS ARTICLE:
Introduction
At Cleo, data matters. In fact, “iterate with data” is one of our values. As Engineers, we need to make sure that every team has access to the data they need.
Our main production database is postgresql. This supports our application and contains our user data. In addition, we use redshift for a lot of our analytics workloads since it’s a column oriented database that can be the right fit for a lot of different query patterns that postgres is less well suited to.
We built a new tool called re_dms in order to allow streaming replication of data from postgres to redshift. Here, we’ll outline why we needed this new tool, our technical considerations,and some challenges we overcame.
History
When Cleo started out using redshift, we had a lot less data. Our replication strategy at the time was to use a tool to regularly copy the entirety of our production data over to postgres. After a short while, we needed to switch to having regular incremental loads of our data, with a weekly full load to paper over any inconsistencies.
This approach bought us some time, but couldn’t scale to handle large amounts of data, and it became clear that we needed another approach to handle the ever-increasing volume of data.
The problem
We need to be able to transfer a large amount of data from postgres to redshift, and keep a low latency in order to have it be useful for our analytics workload. Postgres is an OLTP (online transaction processing) database, whereas redshift is an OLAP database (online analytics processing). What this means for our purposes is to do with redshift’s performance characteristics. Redshift cannot handle a large number of DML queries (data manipulation language, inserts/updates/deletes) in a timely fashion in the way postgres could.
Because of this, we need to make fewer, larger loads, rather than a lot of small updates as happens on postgres. All of this informs our design, we need to be able to stream data from postgres, batch the data up, and apply it regularly. Since we’re working on a live database, we also need to be able to handle schema changes, such as adding or removing columns, along with some type conversions between postgres and redshift.
Some further complications to this are how postgres’s logical replication feature handles these DDL changes (hint: it doesn’t) and how the feature handles updates to rows that have unchanged TOASTed columns (hint2: it doesn’t supply the existing value of the toasted column, only that it was unchanged).
The solution
Initially, as we saw that we weren’t going to be able to continue using our existing system, we started looking for a new one. We tried to use amazon’s DMS to continuously replicate our postgres data to redshift. Unfortunately after some testing we found DMS was unable to batch changes in our case, which meant it wasn't performant enough to handle our throughput.
In light of this, we built re_dms to. One of the requirements for the system is to batch changes. In this project we do the batching of changes in memory, and so we decided to use Rust to build this project as it allows fine-grained control of memory usage, along with good concurrency support and good performance.
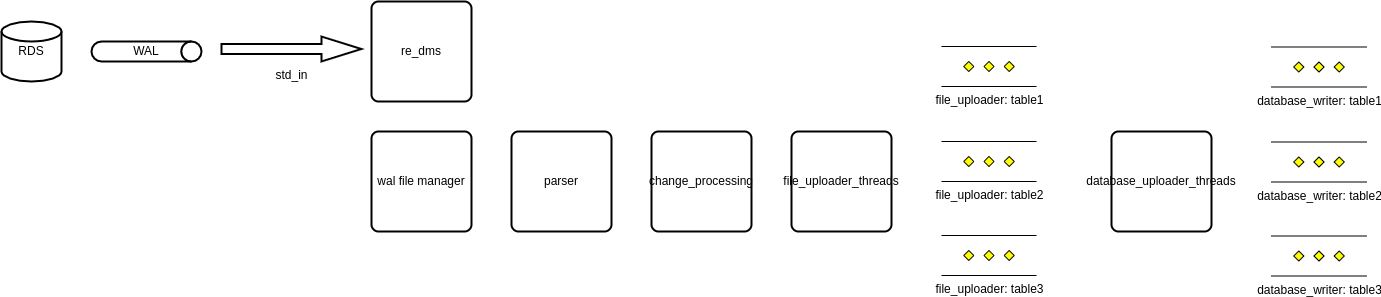
re_dms works by reading from a postgresql replication slot. The first thing it does with this data is to create a write-ahead log so that it can restart without data loss even if there is a powercut and the entire machine goes down.
After this, changes are split by table and batched together (so that an insert followed by an update on the same row, only results in a single change). Periodically, all of these inserts, updates and deletes from all tables get written out into gzipped csv files. When this happens, we switch to a new wal (write-ahead log) section and preserve the previous one until we have finished loading this data into redshift.
We take all of these files and concurrently upload them to s3. These data are then loaded into redshift (also concurrently) while the next section of the wal is being filled.
The complications
This explanation simplifies a few things. It doesn’t explain how we detect schema changes and apply them. While we’re aggregating and batching the data ready to be sent to redshift, we are looking out for if we receive any rows that have either more or fewer columns than the schema previously had.
When that happens, we figure out the exact DDL change that caused this, then load any data we had received before that point. Following this we apply the schema change to the target database, and then will load any subsequent data that has the new schema.
Another complication is the TOASTed columns. When this happens we don’t have all the data for the row locally, so we need to issue an update containing all of the columns other than the unchanged toast column. The same table might have updates that do change the TOAST column, so in that case we would need to have two different updates to do, with different sets of data.
In the arbitrary case we need to do an update for every subset of changed or unchanged toast columns, and have separate data for each of these. That’s exactly what we did, which solved the problem nicely.
How to use
If this sounds like an interesting tool to you, feel free to check it out. Our github page includes instructions, along with some tools that might be helpful including:
A Makefile and docker build environment (to ensure dev prod parity).
A systemd service to handle running the application.
Ansible scripts to handle setting up a server
Integration with an error reporting service (rollbar)
Integrated metrics, and metric configuration (cloudwatch)
We’re always hiring Engineers at Cleo. Explore careers with us here.
You didn’t hear it from me, but Cleo Engineers aren’t perfect. We have bugs. We have quite a few of them. Our relentless focus at Cleo is to make it as simple and joyful as possible for our users to level up their relationship with money.