Adnan, senior data scientist, outlines how we're integrating support into Cleo's chat using AI.
IN THIS ARTICLE:
Introduction
At Cleo, we understand that timely, and efficient customer service is not just an add-on— it’s integral to ensure that our users are happy.
Until recently, Cleo users who needed help found themselves faced with a long list of FAQ articles on Cleo's website. Or, they had to navigate to Intercom (our customer contact platform) for what could turn into a long interaction with a support representative.
Being a chatbot, Cleo's users naturally expected her to resolve their queries directly within the chat interface. So, we’ve committed to integrating support directly into the chat, with the aims of reducing customer service contact rates and enriching the user experience.
We’ve seen great results already. By integrating support into Cleo’s chat, we’ve reduced the number of user queries coming into Intercom by 20%. This gives our customer support agents more time to support users with more complex queries.
The Challenge
Our challenge was to transform the comprehensive information in Intercom's FAQ articles into quick and accurate responses within Cleo's chat. This demanded a system that could produce relevant answers to user queries, without interrupting their chat experience.
The goal was to move from a model where users navigated through a sea of generalized information to a more user-centric experience which offers personalized responses.
The Solution
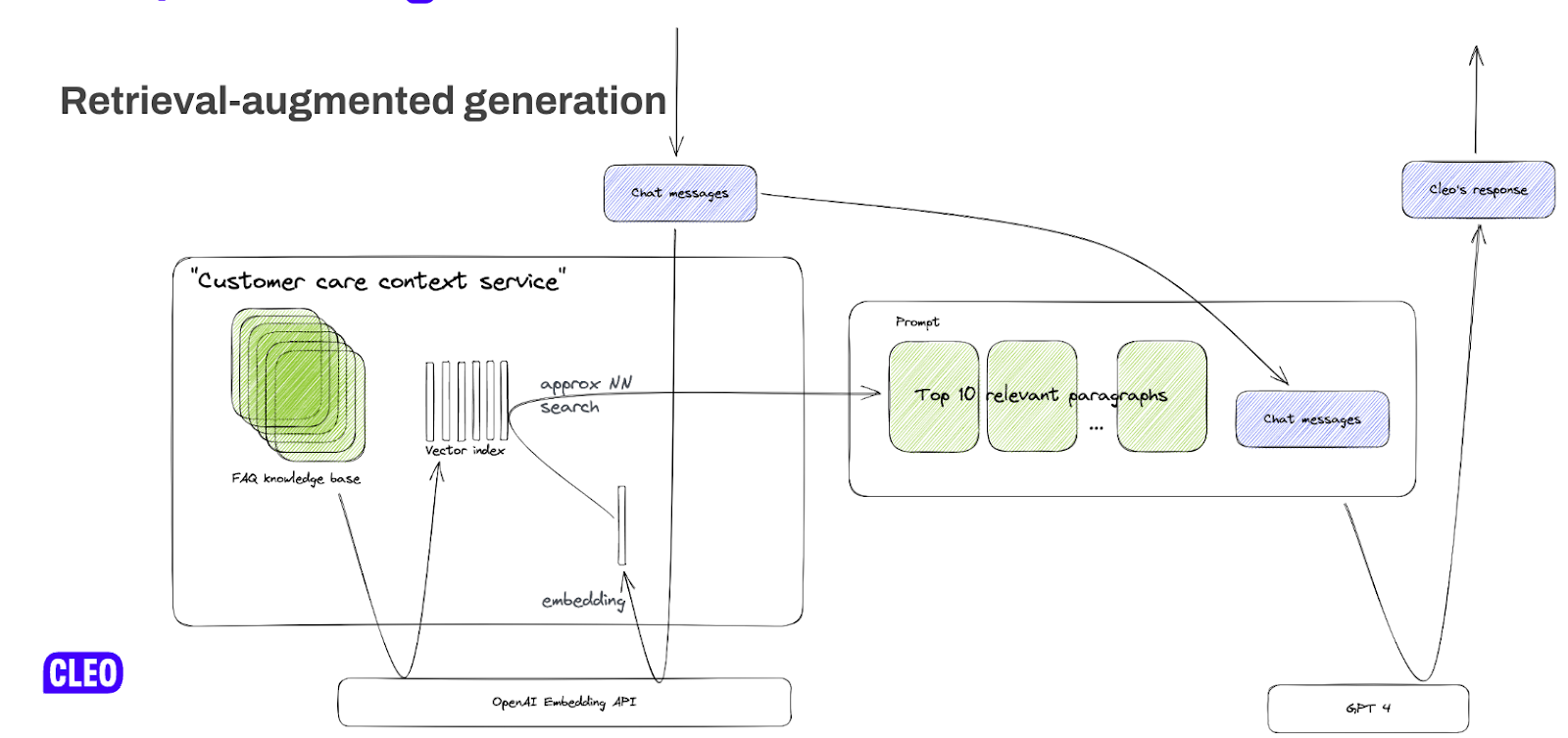
Our solution anchors on a strategy called retrieval-augmented generation. This involves two key steps:
We employ semantic search, which helps find relevant FAQ articles based on the 'meaning' of the user's query.
These articles are then given to GPT-4, a large language model (LLM), as extra context along with the user's question and chat history. The GPT-4 generates the final response by pulling key information from the provided context.
This step-by-step process helps ensure that the responses are not only accurate but are tailored to the user's specific query.
Let's dive into how we’re doing this:
Data Extraction and Preprocessing
We used the Intercom API to extract FAQ articles written in HTML format. We used several open-source libraries, such as beautifulsoup4 for HTML parsing, html2text for HTML to text conversion, and tiktoken for tokenizing the text.
Initial Setup
Our first step involves using a tokenizer that is compatible with the LLM we are using.
A tokenizer's job is to split the input text into smaller chunks (tokens), which the model can understand. We're using the cl100k_base tokenizer in this case. This is required to ensure the max_length of the generated context remains in required range.
Preprocessing HTML Content
Next, we process the HTML content of each FAQ article.
Since the goal is to extract question-answer pairs, we need to identify questions and corresponding answers in the text. For this, we use functions that take a BeautifulSoup object, a Python library for parsing HTML and XML documents, and extract question-answer pairs by identifying question and answer blocks in the HTML content.
Text Cleaning
We then perform further text cleaning operations on the extracted question-answer pairs. For example, at this stage we may remove specific strings from the text that are considered unhelpful for the context of the application.
This step helps our model to get the most relevant and clean data, improving the quality of its outputs.
Storing Extracted Information
Each question-answer pair is then stored in a structured format along with metadata like the article's name, description, and the number of words and tokens in the question and answer.
We also store the number of words and tokens in the text, which can be helpful for downstream tasks.
Semantic Search with GPT Embeddings and Faiss Index
At the heart of Cleo's solution is the integration of state-of-the-art technologies which improve the efficiency and accuracy of information retrieval. This component of the system has two key steps: vectorising the FAQ knowledge base, then using the vector index to identify the most relevant question-answer pairs in real time.
Firstly, the entire FAQ knowledge base, consisting of question-answer pairs, is transformed into a numerical representation using GPT embeddings.
This process essentially translates the human language-based FAQs into a language that machines can understand and process efficiently. The outcome is a set of vectors—points in a multi-dimensional space—that retain the semantic meaning of the original text.
Once vectorised, these embeddings are stored in a Faiss Index, a library developed for efficient similarity search and clustering of dense vectors. It excels at identifying vectors that are closest to a given vector in multi-dimensional space.
In this case, it’s used to find the question-answer pairs that are semantically closest (based on cosine similarity) to the user's query.
As for live user requests, they are first passed through an intent recogniser using a GPT-3 fine-tuned model. If it identifies that the user's intent is to seek help from the FAQ, the user's query is immediately converted into its equivalent GPT embedding and the Faiss Index searches to retrieve the most relevant question-answer pairs.
The process doesn't end there. To further improve the user's experience, we have integrated a GPT-4-powered chatflow into Cleo.
This takes the relevant FAQ entries identified by the semantic search, combines them with the user’s chat history, and creates a context-rich prompt. This prompt is then fed to a GPT-4 model, which generates a precise and context-aware response for the user in the chat.
By using these advanced techniques and technologies, Cleo can now deliver swift, accurate, and context-aware responses in chat, improving the user experience and reducing the need for human intervention.
At Cleo we think that the deliberate, conscious and careful accumulation of tech debt is a powerful tool that lets us ship code and value to our users faster. Fell explains how we manage our technical debt.
Cassie explains the difference between config programming - programming in an ideal world, and vibes programming - programming in reality. Guess which one we love at Cleo?